In statistics, a Moving Average is used to analyze a set of data points by creating a series of averages of different subsets of the full data set.
Given a data series and fixed subset size(N), the first element of Moving Average is obtained by averaging the initial fixed subset (first N elements) of number series. Then the subset is move forward by 1 element, removing the first element and adding the N+1th element of the subset, and average is calculated for the 2nd element of the Moving average. And the process is repeated over the entire data series.
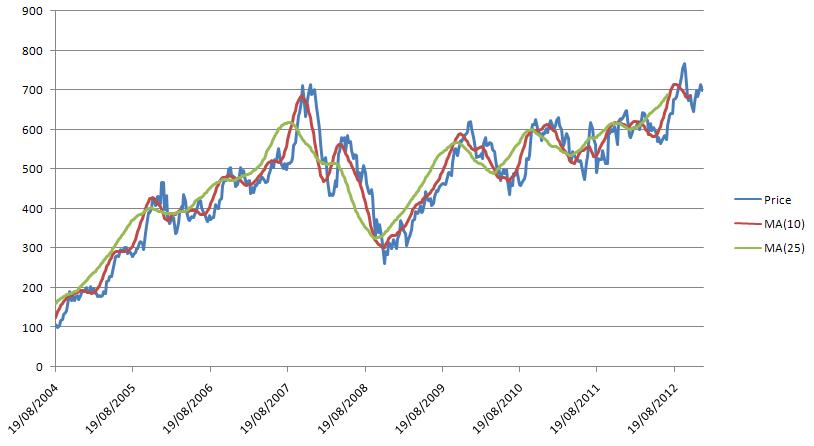
Following graph depicts the Moving Average of Google Weekly closing price for 8 years for window size 10 & 20.

Moving Average is used commonly for analyzing the short term fluctuations from a time series data and highlighting the long term trends. It can be easily seen in the above graph that the line MA(20) is smoothing out a lot of fluctuation as compared to the MA(10).
Moving averages help smooth price action and filter out the noise. They also form the building blocks for many other technical indicators and overlays, such as the McClellan Oscillator and Bollinger Bands.
Types of Moving Average :
- Moving average (SMA)
- Cumulative moving average (CMA)
- Weighted moving average
- Exponential moving average (EMA)
Simple moving average (SMA) and Exponential moving average (EMA) are the most popular type of Moving Average.


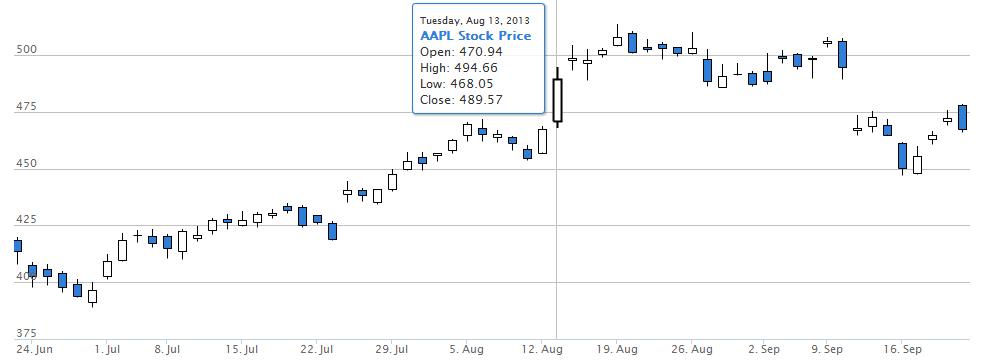
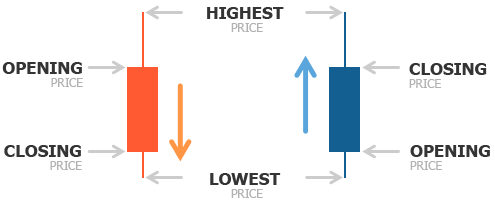



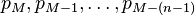 then the formula is
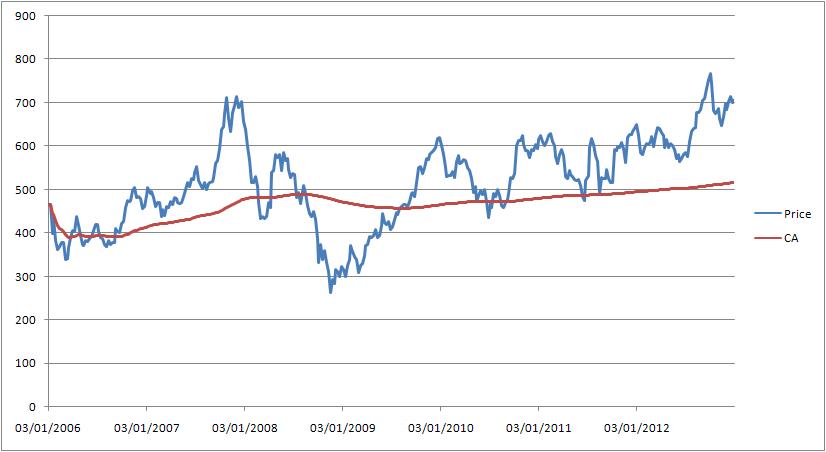
then the formula is