A cumulative moving average, computes the running averages of an ordered datum stream.
For example, an investor may want the average price of all of the stock transactions for a particular stock up until the current time. As each new transaction occurs, the average price at the time of the transaction can be calculated for all of the transactions up to that point using the cumulative average, typically an equally weighted average of the sequence of i values x1, …, xi up to the current time:

The new cumulative average when a new value xi+1 arrives can be calculated using the formula:

Following is an example of cumulative moving average of Google prices.

Cumulative average in q
KDB provides a built in function avgs (running averages) to calculate the cumulative averages.
q)avgs 17 23 44 12 2 36 37 44 28 20 17 20 28 24 19.6 22.33333 24.42857 26.875 27 26.3
If you are Sachin Tendulkar fan then you would be interested to see how he managed to keep CMA of his ODI runs near to 40.

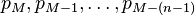 then the formula is
then the formula is





 ), but most often the median.
), but most often the median.



